

 Kategorie:
Kategorie: 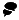 Translate EN
Translate EN
(Dieser Artikel beruht auf der Beta 2 von Exchange 2007. Einige Details können daher überholt sein.)
Microsoft Exchange 2007 führt zwei neue Techniken ein, die auf die Steigerung der Verfügbarkeit zielen. Es handelt sich hier um "Local Continuous Replication" und "Clustered Continuous Replication".
Beide Szenarien bauen auf der Replikation der Transaktionsprotokolldateien (Logs) auf. In einem Fall werden die Logs auf dem selben Server dupliziert und in eine Kopie des Informationsspeichers (IS) eingebaut, im anderen Fall werden die Logs über das Netzwerk zu einem anderen Server übertragen und dort in eine Kopie des IS eingebaut.
Begriffe
Um den Aufbau und die Funktion dieser Technologien zu verstehen, müssen zuerst einige Begriffe definiert werden.
HA Cluster
http://de.wikipedia.org/wiki/Computercluster#HA_Cluster
Der Microsoft Cluster (MSCS) ist ein so genannter "shared nothing" Cluster: Zur selben Zeit greifen nie mehrere Knoten auf dieselbe physikalische Festplatte zu. Der MSCS installiert dazu einen Dienst "Cluster Service" und zwei "Non-Plug and Play Drivers" mit den Namen "Cluster Disk Driver" und Cluster Network Driver". Der Dienst und die Geräte kontrollieren den Zugriff auf die gemeinsamen Festplattenressourcen.
Im Falle eines Exchange 2003 Clusters wird die Exchange-Software auf jeden teilnehmenden Knoten lokal installiert und erst danach der so genannte "Exchange Virtual Server (EVS)" erzeugt. Die Exchange-Datenbanken, Logs, SMTP, MTA und Indexverzichnisse werden dabei auf einer gemeinsamen Festplatte angelegt, und für den EVS wird im Active Directory ein Computerkonto erstellt. Die Verwaltung des Clusters erfolgt über den Cluster Administrator.

Abbildung 1: Exchange 2003 Cluster im Cluster Administrator
Der EVS selber wird fast wie ein normaler Exchange 2003 Server über den Exchange System Manager verwaltet.
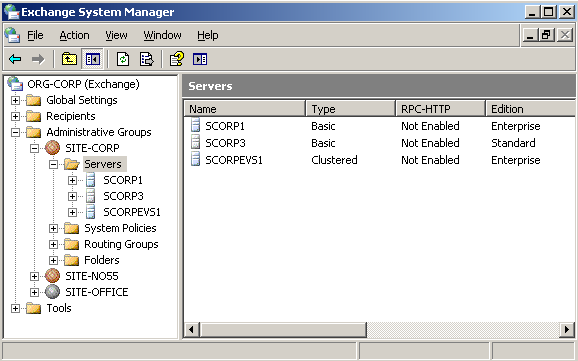
Abbildung 2: Exchange 2003 Cluster im Exchange System Manager
Failover / Failback
Schwenkt eine Clusterressource (manuell oder durch Ausfall eines Knotens) zu einem anderen Knoten, ist das der "Failover". Wird die Ressource zurück zum ehemaligen Besitzer geschwenkt, nennt man das den "Failback". Die Exchange-Datenbanken werden im Falle des kontrollierten "Failovers" heruntergefahren, sind dann im Status "Clean Shutdown", die Festplatten werden dem anderen Knoten übergeben, und dieser stellt die Datenbanken bereit.
Falls der Knoten ausfällt, der den EVS hält, befinden sich die Informationsspeicher im Zustand "Dirty Shutdown". Ein anderer Knoten im Cluster übernimmt die EVS Ressource automatisch, führt das Softrecovery aus und stellt dann die Datenbanken bereit.
Quorum
http://de.wikipedia.org/wiki/Quorum_(Informatik)
Im Falle des MSCS darf nur derjenige Knoten den Cluster bilden, der Zugriff auf das Quorum besitzt. Weitere Knoten können danach dem Cluster beitreten (join). Zugriffsversuche auf das Quorum durch die beitretenden Knoten werden durch den Besitzer des Quorums abgewehrt. Das Quorum löst also das "Split Brain Problem", d.h. es verhindert, dass sich zwei unabhängige Instanzen des Clusters bilden und versuchen dieselbe Ressource online zu nehmen. Microsoft nennt einen Cluster, der mit einer gemeinsamen Festplatte als Quorum arbeitet, intern einen "Vanilla Cluster".
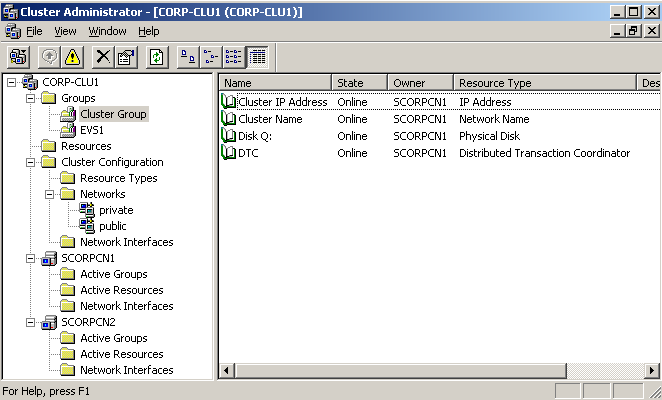
Abbildung 3: Clustergruppe mit der Quorum Disk (Q:)
Majority Node Set (MNS)
In diesem Fall existiert keine explizite Festplatte für das Quorum, d.h. man braucht hier keine spezielle und teure Hardware um den gemeinsamen Festplattenzugriff herzustellen. Aus Sicht des Clusters liegt dann das Quorum lokal (%systemroot%\cluster\ResourceGUID). Die Clusterkonfiguration wird über das Netzwerk zum lokalen Quorum jedes Knotens repliziert.
Schwieriger ist in dem Fall das Erkennen des "Split Brain Problems", da es in diesem Fall nicht DIE entscheidende Stimme des traditionellen Quorums gibt. Im MNS Cluster werden dazu Mehrheitsverhältnisse verwendet. Nur der Teil des Clusters überlebt, in dem mehr Knoten miteinander kommunizieren können als im anderen Teil. Der andere Teil stoppt jeweils den Cluster Service.
Werden die Knoten eines MNS Clusters gestartet, startet der erste Knoten den Cluster Service. Da er aber zu diesem Zeitpunkt keine Mehrheit sieht, stoppt der Cluster Service wieder. Standardmäßig startet der Cluster Service nach einer Minute wieder in der Hoffnung, dass auch die anderen Knoten jetzt soweit sind (und er wiederholt dies jede Minute). Sobald die Mehrheit der Knoten über das Netzwerk miteinander kommunizieren kann, wird der Cluster gebildet, und die Cluster-Ressourcen können online gehen.
Der MNS Cluster ist also erst ab drei Knoten sinnvoll. Würde im Falle eines Zwei-Knoten-Clusters ein Knoten ausfallen, dann besäße der verbleibende Knoten keine Mehrheit und stoppte seinen Cluster Service ebenfalls. Somit wäre der Cluster sinnlos. Ein Cluster-Update, s. File Share Witness, adressiert dieses Problem.
File Share Witness
Dieses Feature wird durch einen Cluster-Update bereitgestellt und löst im Falle des Zwei-Knoten-Clusters das Problem der Mehrheitsverhältnisse. In diesem Fall wird eine Dateifreigabe auf einem Server, der nicht zum Cluster gehört als dritte Stimme (Witness = Zeuge) herangezogen, um die Entscheidung "Welcher Server lebt weiter?" zu treffen. Das Vorhandensein des "Zeugen" führt dazu, dass auch ein Clusterknoten alleine lebensfähig ist, weil er zwei von drei Stimmen besitzt (sein lokales MNS Quorum und den Share) und damit eine Mehrheit hat.
http://support.microsoft.com/kb/921181
Exchange 2007 Features
Der Exchange Datenspeicher besteht aus Speichergruppen (mit jeweils einem eigenen Transaktionsprotokoll) und einer Datenbankdatei pro Informationsspeicher (.edb). Die Technik des Einspielens von Logs in einen Informationsspeicher (IS) stammt ja aus der Wiederherstellung von IS. Dabei werden Logs, die nach dem Backup entstanden sind, der Reihe nach in einen IS eingespielt.
Single Copy Cluster
Mit "Singe Copy Cluster" ist der "Vanilla Cluster" gemeint, d.h. die Technik ist dieselbe wie beim Exchange 2003 Cluster.
Local Continuous Replication (LCR)
In diesem Fall wird auf dem Exchange 2007 Server selber, auf einer anderen physikalischen Festplatte, eine zweite Instanz des IS mitgeführt. Dieser IS ist allerdings nicht online, er befindet sich praktisch immer im Recoverymodus. Die Logs werden über einen Replikationsdienst in dessen Logverzeichnis kopiert, geprüft und in den IS eingebaut. Falls eine Speichergruppe über den LCR Mechanismus repliziert werden soll, dann darf sich darin nur ein IS befinden. In der Abbildung ist ersichtlich, dass für eine Speichergruppe "First Storage Group" eine lokale Replikation eingerichtet ist (Copy Status: Healthy).
Abbildung 4: LCR in der Exchange 2007 Management Console
Die Schattendatenbank ist ständig im Zustand "Dirty Shutdown" da immer Logs eingespielt werden.
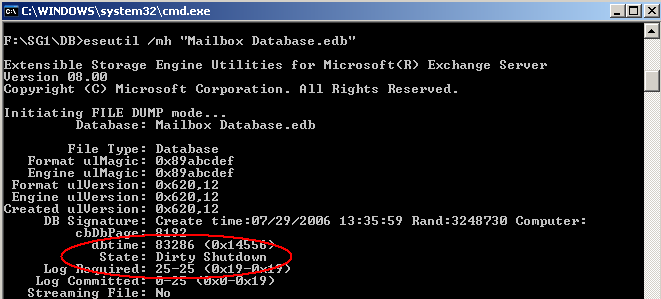
Abbildung 5: IS Replik im Recoverymodus
In der Abbildung sind die Logverzeichnisse der laufenden Speichergruppe und der replizierten Speichergruppe dargestellt. Die Logs werden in diesem Fall also von E:\SG1\LOGS nach F:\SG1\LOG repliziert. Bevor die Logs in die Schattendatenbank in F:\SG1\DB eingebaut werden, werden sie auf Integrität geprüft. Dies geschieht im "inspector"-Verzeichnis.
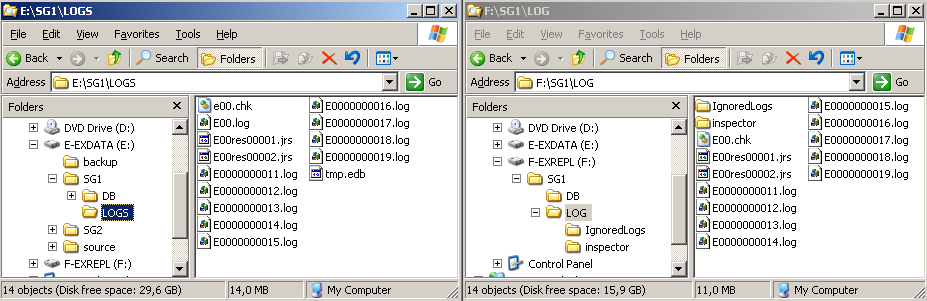
Abbildung 6: Links, die Online-Logs. Rechts, die replizierten Logs.
Der aufmerksame Leser wird feststellen, dass im replizierten Datenbestand (rechts) ein wichtiges Logfile fehlt. "E00.log" ist das Logfile, das gerade aktuell von Exchange 2007 verwendet wird, dieses ist geöffnet und kann deswegen nicht repliziert werden. Der replizierte IS hängt deswegen immer ein wenig hinter dem Online-IS her, und im Falle eines Crashs der E:-Partition ist ein Teil der Daten verloren. Die Logs sind im Falle Exchange 2007 allerdings nur noch 1 MB groß (bei allen Vorgängerversionen waren sie 5 MB), so dass der Verlust auf ein Minimum beschränkt ist. Fällt jetzt die Festplatte des Online-IS aus, kann auf die Kopie umgestellt werden, und man erspart sich den Restore. Das Umschalten ist ein manueller Vorgang und je nach Ausfallsszenario sind unterschiedliche Aktionen durchzuführen.
Hinweis: Der Transport Dumpster (Details s.u.), der eine Rolle im CCR-Szenario spielt, kann beim LCR nicht verwendet werden (Stand der Beta-Doku).
Cluster Continuous Replication (CCR)
Hauptbestandteil dieses Artikels soll aber das CCR Szenario sein, das alle vorab beschriebenen Techniken vereinigt.
Der Exchange 2007 CCR-Cluster besteht aus genau zwei Clusterknoten. Es ist keine gemeinsame Festplatteninfrastruktur notwendig, der Cluster arbeitet mit dem "Majority Node Set Quorum (MNS)" und "File Share Witness". Das Datenbankreplikat liegt in diesem Falle nicht mehr auf demselben Server, sondern auf einem zweiten Server.
Ausgangssituation
Die Exchange-Organisation, in die der Cluster aufgenommen wird, existiert schon, d.h. Schemaerweiterung etc. ist schon durchgeführt worden. Es befinden sich im Moment ein Exchange 2003 und ein Exchange 2007 Server in dieser Organisation.
Beispielcluster
Der Beispielcluster wird folgendermaßen aussehen:
- Knoten1: bhfe7n1 (Public-LAN: 10.10.10.96 / Private-LAN 192.168.10.96)
- Knoten2: bhfe7n2 (Public-LAN: 10.10.10.97 / Private-LAN 192.168.10.97)
- Clustername: bhfe7clu1 (10.10.10.98)
- EVS Name: bhfe7vs1 ( 10.10.10.99)
- Servicekonto: zzzclu2svc
- Witness Server: bhfdc1
- Witness Freigabe: MNSShare
Step 1: Vorbereitung
Basisinstallation
Die beiden Knoten werden mit Windows Server 2003 SP1 installiert. Danach wird der IIS nachinstalliert (Achtung: kein SMTP oder NNTP Dienst aus alter Gewohnheit mitinstallieren). Zusätzlich wird auf jedem Knoten die PowerShell und das .NET Framework 2.0 installiert.
Clusternetzwerk
Die Netzwerke für den Cluster werden vorbereitet. Die Namen der Netzwerkkarten werden von "LAN-Verbindung" auf "Public" bzw. "Private" umbenannt. Das "Private"-Netz wird ohne Gateway, DNS usw konfiguriert. Das "Public"-Netz wird komplett konfiguriert.
Abbildung 7: Netzwerke umbenennen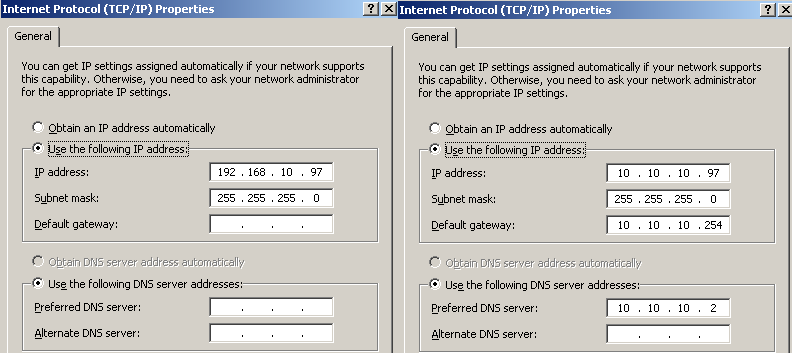
Abbildung 8: Links "Private LAN". Rechts "Public LAN"
Für das "Private"-Netzwerk wird NetBIOS deaktiviert und die Bindungen für "Client for Microsoft Networks" und "File and Printer Sharing" entfernt. Das "Public"-Netzwerk wird an die oberste Stelle geschoben.
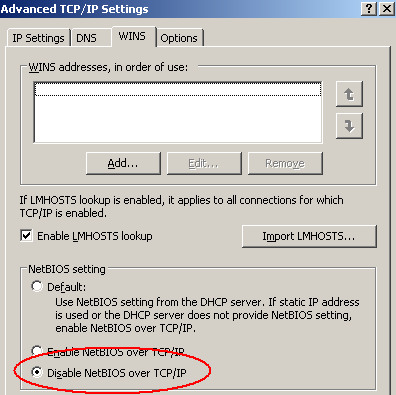
Abbildung 9: NetBIOS für "Private" Netzwerk deaktivieren
Abbildung 10: "Public" ganz oben, Bindungen bei "Private" entfernt
In einem ersten Test werden jetzt gegenseitig die "Private"- und "Public"-IP-Adressen angepingt.
File Share Witness
Jetzt wird der "Zeuge" wird vorbereitet ("File Share Witness"). Dazu wird auf einem dritten Server eine Freigabe "MNSFileShare" angelegt. Das Cluster-Service-Konto bekommt die Freigabe- und NTFS-Berechtigung "full control". Microsoft empfiehlt, diese Freigabe auf einem Exchange 2007 Server mit der Hub-Server-Rolle anzulegen.
Servicekonto
Zum Abschluss muss das Servicekonto entsprechende Berechtigungen bekommen. Es muss auf den Clusterknoten in die lokale Administratorengruppe aufgenommen werden und in der Exchange 2007 Organisation die Rolle "Exchange Administrator" für den EVS delegiert bekommen. Hier beißt sich im Moment noch die Katze in den Schwanz, die Rolle kann noch gar nicht delegiert werden, weil es den EVS zu diesem Zeitpunkt noch nicht gibt. Also kurzerhand das Servicekonto in die die Gruppe der "Domain Admins" aufnehmen.
Exchange-Datenpartitionen und -Verzeichnisse
Die Festplattenpartitionen für die Ablage der Exchange-Datenbanken und -Transaktionsprotokolle können auch schon vorbereitet werden. In Beispiel wird dazu die Partition E:\ verwendet. In E:\SG1\DB kommt später der Informationsspeicher, in E:\SG1\LOG die Transaktionsprotokolle. Jeder Clusterknoten wird identisch konfiguriert.
Step 2: Cluster einrichten
Nachdem alle netzwerkseitigen Voraussetzungen eingerichtet sind, kann der Cluster aktiviert werden. An einem der Clusterknoten wird der "Cluster Administrator" aufgerufen, dort der Cluster erzeugt, dabei der Clustername und die Cluster IP Adresse definiert.
Clusterkonfiguration
Achtung: bevor "Finish" geklickt wird, muss das Quorum auf "Majority Node Set" umgestellt werden. Danach ist der Cluster erzeugt, und es kann mit dem Cluster Administrator und "New Node" der andere Knoten in den Cluster aufgenommen werden. Im Endergebnis sollte jetzt eine Clustergruppe mit dem Namen "Cluster Group" online sein und sich zwischen Clusterknoten hin und her verschieben lassen. Die IP-Adresse (10.10.10.98) und der Clustername (bhfe7clu1) wandern dabei mit.
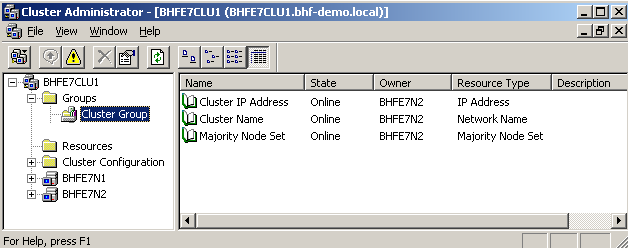
Abbildung 11: Basisclusterkonfiguration ist fertiggestellt
Clusternetzwerk
Die Clusternetzwerke werden jetzt noch in die richtige Reihenfolge gebracht. Ein Rechtsklick auf den Clusternamen, Eigenschaften, zeigt diese Konfiguration. Das "Private"-Netzwerk gehört ganz nach oben.
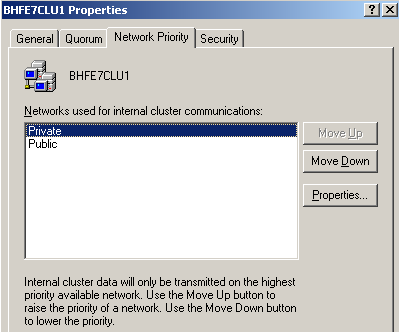
Abbildung 12: Priorität der Netze
Das "Private"-Netzwerk wird für "Cluster Only"-Benutzung konfiguriert. Das "Public"-Netzwerk wird für beide Verwendungen (Cluster Heartbeat und Client Zugriff) konfiguriert.
File Share Witness
Jetzt wird das "File Share Witness" Feature installiert. Also Download des Updates von http://support.microsoft.com/kb/921181 und Installation auf jedem Knoten inkl. Reboot. Nachdem beide Knoten wieder online sind, kann das Feature konfiguriert werden. Dazu muss man sich auf die Kommandozeile bewegen und ruft auf einem Clusterknoten die Kommandozeile "cmd.exe" auf:
cluster.exe res "Majority Node Set" /priv MNSFileShare=\\bhfdc1\MNSFileShare
Danach verschiebt man die bisher einzige Clustergruppe auf den anderen Knoten und wieder zurück, um die Clusterkonfiguration zu aktivieren. Wenn alles erfolgreich verlaufen ist, befinden sich in dieser Freigabe Dateien und Verzeichnisse. Die erfolgreiche Konfiguration kann ebenfalls mit
cluster res "Majority Node Set" /priv
geprüft werden. Die Freigabe sollte in der Ausgabe erscheinen.
Step 3: Exchange-Installation
Erster Knoten
Die Exchange-2007-Installation wird jetzt auf dem ersten Knoten gestartet.
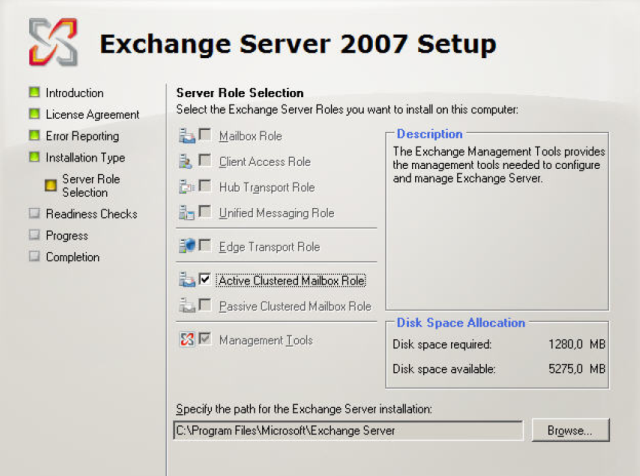
Abbildung 13: Exchange 2007 Installation auf dem ersten Knoten
Während der Installation werden die Clusterparameter definiert:
- Name des virtuellen Exchange-Servers: bhfe7vs1
- IP-Adresse des virtuellen Exchange-Servers: 10.10.10.99
- Datenbankpfad: E:\SG1\DB
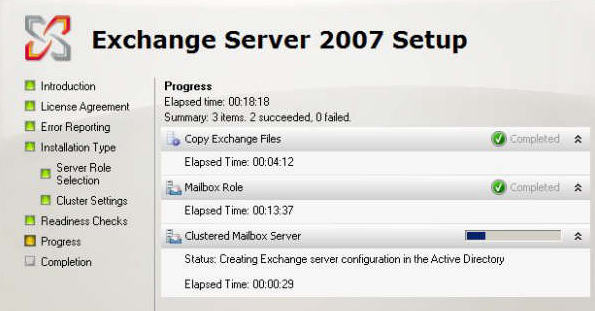
Abbildung 14: Clusterkonfiguration wird durchgeführt
Das Exchange-Setup legt die Cluster-Ressourcen automatisch an.
Logs verschieben
Ist die Installation erfolgreich abgeschlossen worden, werden im nächsten Schritt die Logs in ein eigenes Logverzeichnis verschoben. Dies lässt sich in dem Fall leider nicht mit der Exchange Management Konsole durchführen sondern muss manuell gemacht werden. Dazu wird die Bereistellung des IS aufgehoben (dismount), dann die Konfiguration der Speichergruppe per Exchange Management Shell geändert:
[MSH] C:\>move-StorageGroupPath
-Identity:"bhfe7vs1\First Storage Group"
-LogFolderPath:"E:\SG1\LOG"
-SystemFolderPath:"E:\SG1\LOG"
-configurationonly:$true
Die Logs müssen jetzt manuell in das neue Verzeichnis verschoben werden. Danach kann der IS wieder bereitgestellt (mount) werden.
Hinweis:
Die Logs verschiedener Speichergruppen dürfen sich nicht im selben Verzeichnis befinden.
Zweiter Knoten
Jetzt kann das Exchange-Setup auf dem zweiten Knoten gestartet werden. Dort wählt man "Passive Clustered Mailbox Role" aus, und der Rest geht von selber. Endergebnis ist jetzt eine zweite Clustergruppe mit den Exchange-2007-Ressourcen. In der Abbildung ist zusätzlich schon eine zweite Speichergruppe zu sehen.
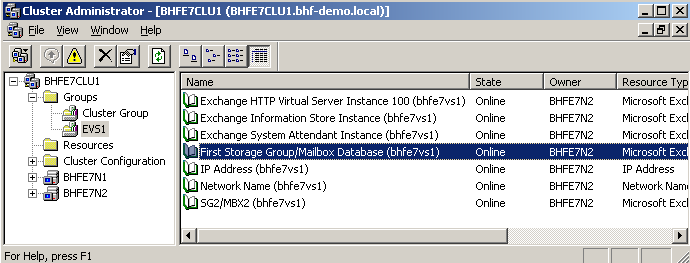
Abbildung 15: Virtueller Exchange Server im Cluster Administrator
Der Netzwerkname des EVS "bhfe7vs1" taucht jetzt, wie beim Exchange-2003-Cluster, als Computerobjekt im Active Directory auf. In der Exchange 2007 Management Konsole wird der EVS als "clustered" Exchange Server dargestellt.
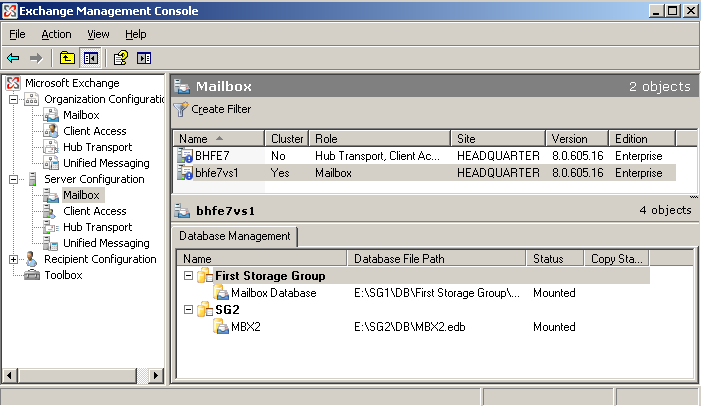
Abbildung 16: Exchange CCR Cluster in der Management Konsole
Im Exchange-Datenverzeichnis des zweiten Knoten befinden sich jetzt schon die Schattendatenbank und einige Logs.
Testpostfach
Nachdem jetzt ein Testpostfach in den geclusterten Speicher verschoben und an diesen Empfänger eine 1 MB Mail gesendet wurde, sieht der Zustand auf aktiven und passiven Clusterknoten folgendermaßen aus:
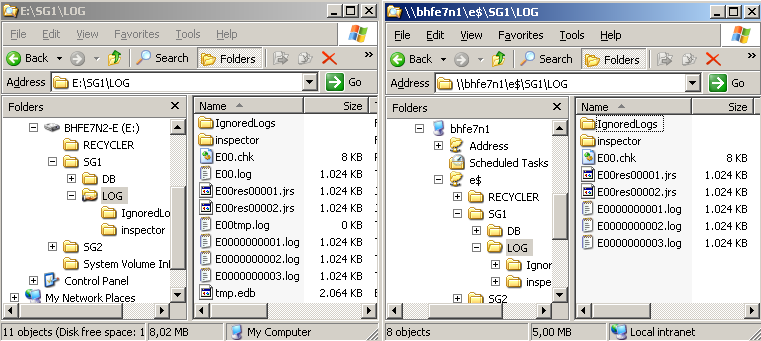
Abbildung 17: Logverzeichnisse. Links der aktive Knoten. Rechts der passive Knoten.
Normalbetrieb
Im Normalbetrieb werden jetzt alle Logs zum passiven Knoten repliziert und dort in die Schattendatenbank eingebaut.
Step 4: Transport Dumpster
Wie schon im LCR-Szenario kann das aktuelle Log der jeweiligen Speichergruppe ("E00.log" im Falle der ersten Speichergruppe) nicht repliziert werden, weil es in Benutzung ist. Jetzt hilft aber ein Mechanismus, der sich "Transport Dumpster" nennt. Dieser ist im CCR Szenario erforderlich, wird aber nicht automatisch eingerichtet. Sinn und Zweck dieses "Zwischenspeichers" ist folgender: Angenommen, der Failover auf den passiven Knoten erfolgt mit Datenverlust, d.h. der aktive Knoten bricht einfach weg und "E00.log" kann nicht repliziert werden. In diesem Fall benachrichtigt der überlebende Knoten, der die Datenbanken online nimmt, den Hubserver in der Site (der den "Transport Dumpster" darstellt). Dieser sendet alle Nachrichten, die er für eine konfigurierbare Zeit und Größe vorhält, noch mal an den EVS. Dieser ist dann so schlau, zu erkennen, welche Nachricht im IS fehlt, um diese dann zuzustellen, oder Duplikate zu verwerfen.
Der Transport Dumpster wird auf dem Hub Server per Management Shell folgendermaßen angelegt:
[MSH] C:\>Set-transportconfig
-MaxDumpsterSizePerStorageGroup 20MB
-MaxDumpsterTime 07.00:00:00
In obigem Beispiel wird der Transport Dumpster auf 20MB und die maximale Aufbewahrungszeit auf sieben Tage konfiguriert. Microsoft empfiehlt momentan die Größe des Dumpsters auf 125%-300% der max. Nachrichtengröße zu konfigurieren (je nach Stelle in der Doku). Die Empfehlung zur maximalen Aufbewahrungszeit schwankt zwischen drei Stunden und sieben Tagen. Welcher Wert von beiden jetzt letztendlich wirkt, ist noch nicht klar.
Die eingestellten Werte werden bei CN=Transport Settings,CN=ORGNAME,CN=Microsoft Exchange,CN=Services,CN=Configuration,DC=domain,DC=tld in den Attributen:
msExchMaxDumpsterSizePerStorageGroup: 20480;
msExchMaxDumpsterTime: 604800;
gespeichert, d.h. es ist eine organisationsweite Konfiguration, die sich auf alle Hub Server auswirkt.
CCR – Einige Beispiele
Geplanter Failover
Ein geplanter Failover wird im Gegensatz zum "Vanilla Cluster" nicht mit dem Cluster Administrator eingeleitet sondern mit der Exchange Management Shell. Der Befehl:
[MSH] C:\>move-clusteredMailboxServer
-Identity bhfe7vs1
-targetmachine bhfe7n1
-MoveComment "nur so zum Test"
schwenkt die Cluster Ressource von Knoten 2 zu Knoten 1.

Abbildung 18: Ansicht im Cluster Administrator während dem Failover
Während des Failover sollte man nicht nervös werden und geduldig abwarten, bis die Speichergruppen von selber online gehen. Der Exchange-Dienst koordiniert den Ablauf.

Abbildung 19: Logverzeichnis vor und nach dem Failover
Da der Failover geplant war, konnte auch "E00.log" nach dem Aufheben der IS-Bereitstellung repliziert und in die Schattendatenbank eingespielt werden. Im Anwendungsprotokoll wird dies dokumentiert.
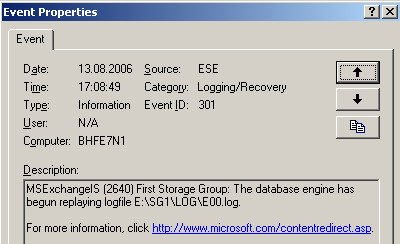
Abbildung 20: Logreplay "E00.log"
Eine Zusammenfassung des Failovers ist ebenfalls im Anwendungsprotokoll festgehalten.
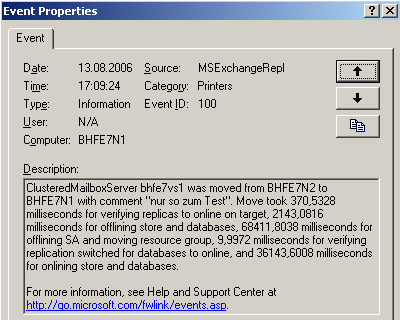
Abbildung 21: Zusammenfassung des geplanten Failovers
Wie sieht der Zustand jetzt aber auf dem anderen Knoten aus (dem jetzigen passiven Knoten)?
Im Logverzeichnis ist überhaupt nichts passiert. "E00.log", "E00.chk" und die anderen Logfiles sind immer noch vorhanden. Solange an dem Online-IS des aktiven Knotens keine Änderungen gemacht werden, bleibt das auch so, nur gibt's so was? Nein, auf jeden Fall nicht für längere Zeit. Es erfolgt also recht schnell nach dem Failover die Replikation in die umgekehrte Richtung. "E00.log" wird während der rückwärtigen Replikation weggeräumt, weil es ja nicht mehr zu Datenbank passt. Es sind ja auf der anderen Seite schon Änderungen durch das dortige "E00.log" geflossen.
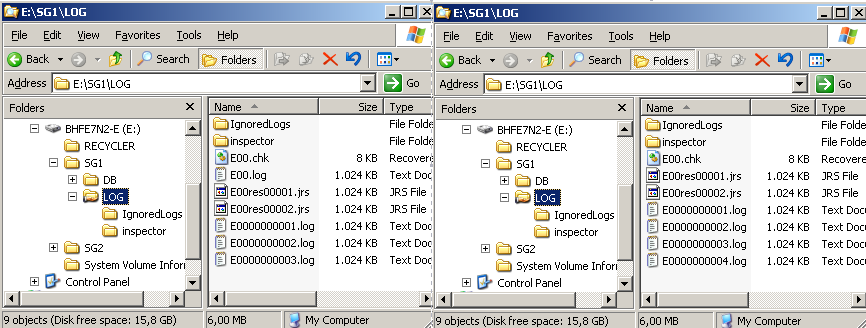
Abbildung 22: "E00.log" wird während der Rückreplikation weggeräumt
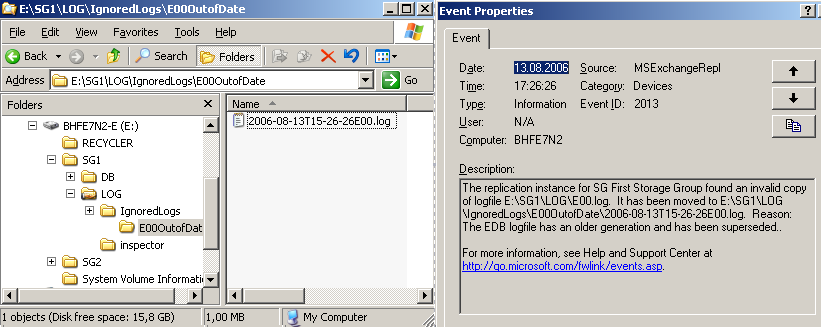
Abbildung 23: "E00.log" wird verschoben im Eventlog festgehalten
Jetzt ist der Cluster bereit für einen geplanten Failback.
Ausfall des aktiven Knotens (Knoten 2)
Die Ausgangssituation ist jetzt folgende: Der aktive Knoten ("bhfe7n2") wird einfach abgeschaltet (in meinem Szenario VPC – Aktion – anhalten), d.h. der Failover muss ohne "E00.log" ablaufen. In diesem Fall ist mit Datenverlust zu rechnen, da die Transaktionen, die sich noch in "E00.log" befinden, nicht repliziert werden können.
Der Failover läuft automatisch ab, nachdem der Cluster Service erkannt hat, dass der aktive Knoten ausgefallen ist. Wenn man im Cluster Administrator den Failover beobachtet, sieht man einige Male, dass die IS-Ressourcen einige Male auf "failed" laufen, bis sie aber zuletzt automatisch online gehen. Natürlich hagelt's jetzt einige Events:
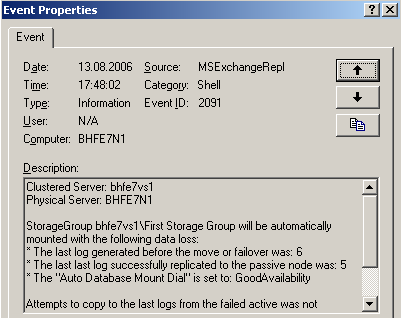
Abbildung 24: Irgendwas stimmt nicht, es fehlen Logs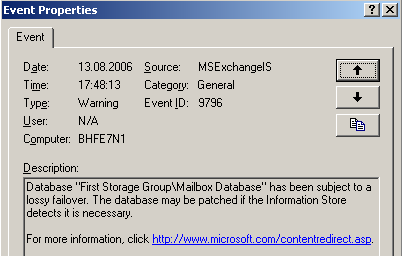
Abbildung 25: Lossy failover, Daten fehlen.
Da Daten verloren gingen, wird jetzt der "Transport Dumpster" benachrichtigt und aufgefordert, ehemalige Nachrichten noch einmal zuzustellen.
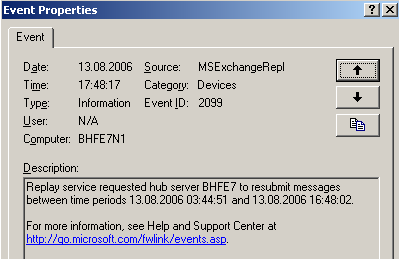
Abbildung 26: Replay wird vom Hub angefordert
Die Anforderung der ehemaligen Mails ist recht großzügig. Das Desaster ist um 17:48 eingetreten. Es werden vom "Transport Dumpster" alle Nachrichten ab 3:44 angefordert. In den Zeitangaben des Eventlog-Eintrags scheint sich Exchange noch ein wenig zu verhauen. Es dürfte dort nicht 16:48:02, sondern 17:48:02 stehen. Die Daten in den Mailboxen sind jedenfalls vollständig. Der "Transport Dumpster" hilft aber nicht in allen Fällen. Hat z.B. der Benutzer gerade einen Eintrag in seinem Kalender vorgenommen, ist dies natürlich nicht im "Transport Dumpster" zu finden (dort sind nur E-Mails). Dieser Eintrag wäre verloren.
Knoten 2 kommt wieder hoch
Was passiert jetzt, wenn man den ausgefallenen Knoten wieder hochfährt (in meinem Szenario VPC – Aktion – fortsetzen)? Er darf seine Datenbanken nicht bereitstellen, weil sie ja auf dem anderen Knoten online sind. Im Eventlog kann man die Aktionen nachvollziehen:
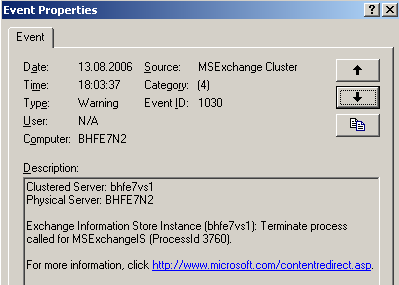
Abbildung 27: Datenbankprozesse werden gekillt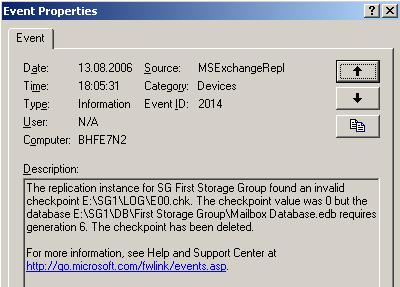
Abbildung 28: Die rückwärtige Replikation wird vorbereitet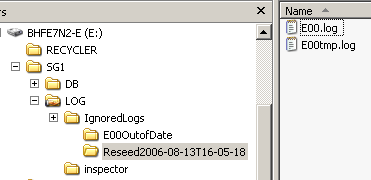
Abbildung 29: Reste werden beseitigt
Replik kann nicht mehr inkrementell aktualisiert werden
Wenn es ganz blöd läuft, dann kann der Replikationsmechanismus die Schattendatenbank nicht mehr durch Logfile-Replay aktuell halten, z.B. dann, wenn ein Log auf dem Transportweg korrupt geht. Die Integritätsprüfung stellt dies fest, bevor sie das korrupte Log einspielt. Jetzt ist eine Lücke in der Logsequenz, und auch folgende Logs können deswegen nicht mehr eingespielt werden.

Abbildung 30: Replik ist nicht mehr inkrementell aktualisierbar
Falls dieser Zustand nicht durch manuelles Kopieren von einzelnen Logs behebbar ist, hilft nur eine kompletter Neuaufbau (seeding = säen): Die produktive Datenbank wird neu auf den passiven Knoten übertragen. Eine Lösungsvariante wäre die Aufhebung der Bereitstellung der Online-Datenbank und manuelles Kopieren des IS auf den passiven Knoten. Die bessere Variante ist allerdings die neuerliche Übertragung per "reseed", weil kein Offlinezustand erforderlich ist. Dazu sind einige manuelle Schritte notwendig:
Schritt 1: Aussetzen der Replikation auf dem aktiven Knoten per:
[MSH] C:\>Suspend-StorageGroupCopy
-Identity "bhfe7vs1\first storage group"
Schritt 2: Löschen der Datenbankdateien und Transaktionsprotokolldateien auf dem passiven Knoten
Schritt 3: "Reseeding" der Datenbankdatei auf dem passiven Knoten per:
[MSH] C:\>Update-StorageGroupCopy
-Identity "bhfe7vs1\first storage group"

Abbildung 31: Reseeding (Neuübertragen) des IS
Schritt 4: Starten der Replikation auf dem aktiven Knoten per:
[MSH] C:\>Resume-StorageGroupCopy
-Identity "bhfe7vs1\first storage group"
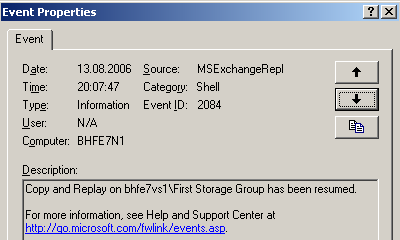
Abbildung 32: Replikation ist wieder intakt
Lessons learned
Sowohl LCR als auch CCR sind superinteressante Technologien, die einen schnellen Wiederanlauf der Exchange-Datenbanken nach einem Teil- oder Totalausfall ermöglichen. Beide Verfahren benötigen keine spezielle Hardwarelösung in Bezug auf Festplattensubsysteme. Das Argument der erforderlichen Ausbildung der Administratoren beim traditionellen "Vanilla Cluster" gilt bei beiden Technologien genauso. Der Administrator muss sich detailliert mit der Datenbanktechnik und Transaktionsprotokollierung auseinandersetzen und die Vorgänge bis ins Detail verstehen, bevor er sich an ein solches Projekt heranwagen kann.
Weitere Punkte, die in diesem Artikel nicht behandelt, wurden spielen eine entscheidende Rolle für den erfolgreichen Einsatz der Replikationstechniken wie z.B.
- Backup und Recovery
- Konsistenzprüfung der replizierten Datenbank
Während der Tests und der Artikelerstellung sind natürlich auch einige Ungereimtheiten und komische Effekte aufgetreten, die bestimmt zum einen im Betastadium des Produkts zu suchen sind, zum Anderen natürlich auch an der Unerfahrenheit, mit dieser Technik umzugehen.
Einige Feinheiten sind noch gar nicht oder nur unvollständig dokumentiert. Nicht aufklären konnte ich die Bedeutung von "Lost Log Resiliency (LLR)". Auf jeden Fall kann wohl dadurch das Risiko von Datenbankinkonsistenzen drastisch vermindert werden. Ich denke dieses Verfahren wird im Falle "Totalausfall des aktiven Knotens" eingesetzt, denn ohne "E00.log" kann normalerweise ein IS (ohne Reparatur) nicht online genommen werden.
http://faq-o-matic.net/?p=680